Falcon CHAT Hugging Face Paper Github DEMO DISCORD
Introduction
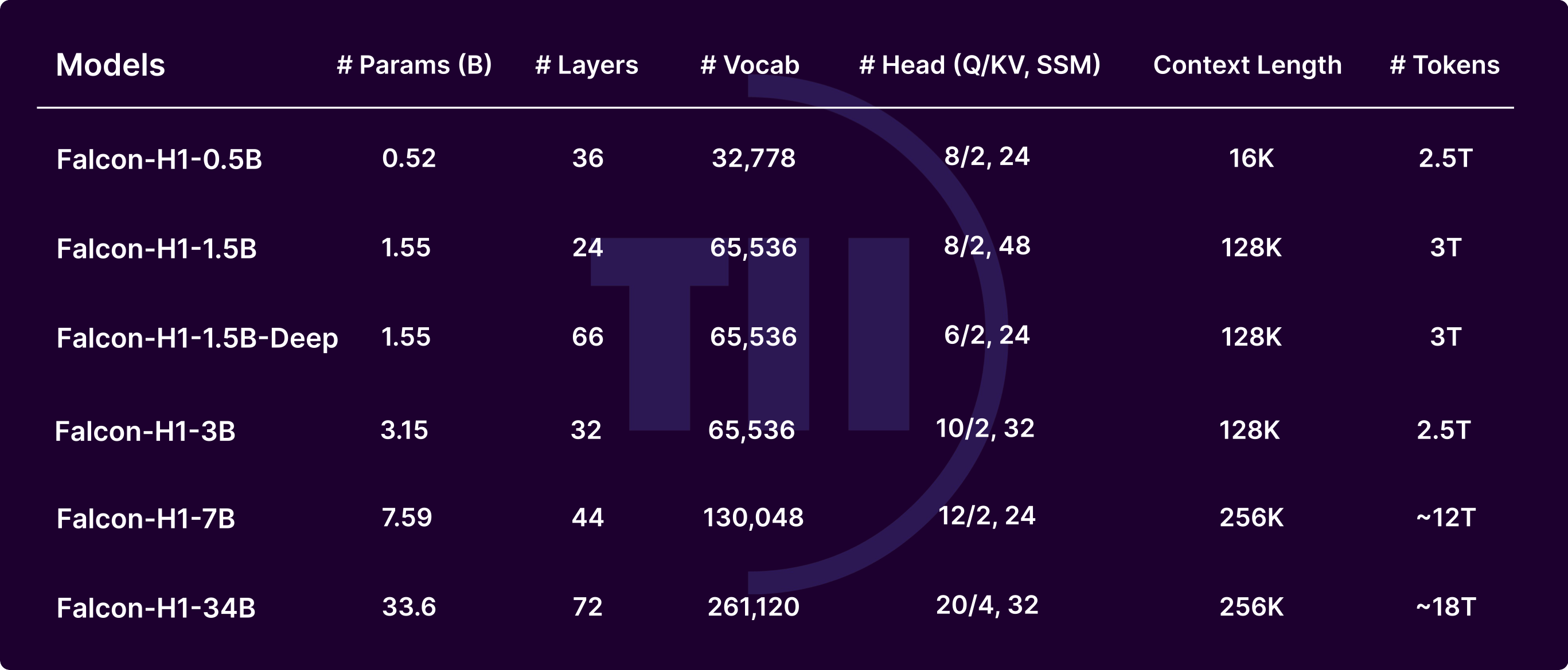
Today, we are proud to introduce the Falcon-H1 series, a collection of six open-source models ranging from 0.5B to 34B parameters, each available in both base and instruction-tuned variants. At the core of these models lies a hybrid architecture that combines the strengths of the classical Transformer-based attention mechanism with the State Space Model (SSM), known for its superior long-context memory and computational efficiency. This architectural innovation is further enhanced by fundamental advancements in training dynamics and data utilization, enabling Falcon-H1 models to deliver uncompromised performance that rivals the top Transformer-based models across all covered size tiers.
In this release, we feature six open-weight models: 0.5B, 1.5B, 1.5B-Deep, 3B, 7B, and 34B, along with their instruct versions. All our open-source models are with a permissive license based on Apache 2.0.
Key Features of Falcon-H1
Hybrid Architecture (Attention + SSM): We combine attention and Mamba-2 heads in parallel within our hybrid mixer block. Importantly, the amount of attention and mamba heads can be adjusted independently, allowing for an optimal attention/SSM ratio. This hybrid design enables faster inference, lower memory usage, and strong generalization across tasks.
Wide Range of Model Sizes: Available in six scales—0.5B, 1.5B, 1.5B-deep, 3B, 7B, and 34B—with both base and instruction-tuned variants, suitable for everything from edge devices to large-scale deployments.
Multilingual by Design: Supports 18 languages natively, including Arabic (ar), Czech (cs), German (de), English (en), Spanish (es), French (fr), Hindi (hi), Italian (it), Japanese (ja), Korean (ko), Dutch (nl), Polish (pl), Portuguese (pt), Romanian (ro), Russian (ru), Swedish (sv), Urdu (ur), and Chinese (zh) — with scalability to 100+ languages, thanks to our multilingual tokenizer trained on diverse language datasets.
Compact Models, Big Performance: Falcon-H1-0.5B delivers performance on par with typical 7B models from 2024, while Falcon-H1-1.5B-Deep rivals many of the current leading 7B–10B models. Each Falcon-H1 model is designed to match or exceed the performance of models at least twice its size, making them ideal for low-resource and edge deployments without compromising on capability.
256K Context Support: Falcon-H1 models support up to 256K context length, enabling applications in long-document processing, multi-turn dialogue, and long-range reasoning.
Exceptional STEM capabilities: Falcon-H1 models deliver strong performance in math and science domains thanks to the focus on high-quality STEM data during training.
Robust Training Strategy: Uses a high-efficiency data strategy and customized Maximal Update Parametrization (μP) to ensure smooth and scalable training across model sizes.
Main Principles behind building Falcon-H1
When embarking on the Falcon-H1 series development, we chose to fundamentally rethink the training approach. While the field of LLM development has converged on many established practices that reliably produce strong models, these conventions were primarily validated on classical transformer architectures. The shift from pure attention mechanisms to a hybrid attention-SSM design represents a significant architectural change, making it uncertain whether these standard practices would remain optimal.
Given this uncertainty, we conducted an extensive experimentation phase, systematically revisiting nearly every aspect of model design and training methodology before launching our final training runs. While we will provide comprehensive details in our upcoming technical report, we’d like to share the key insights that shaped the Falcon-H1 models.
Architecture
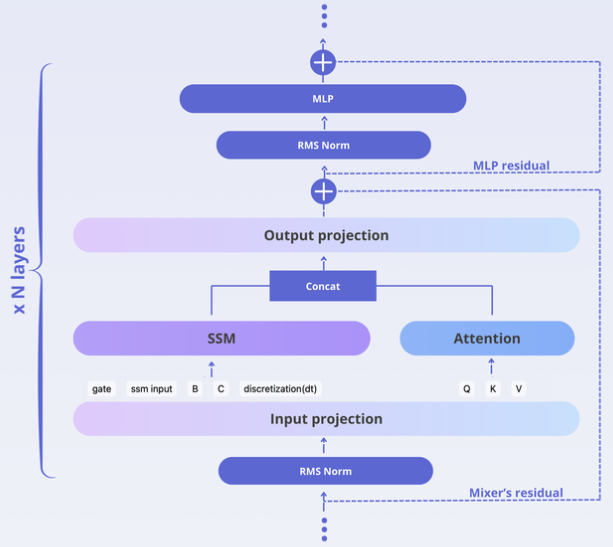
The hybrid attention-SSM models have a larger configuration space of all the parameters that define the model architecture. Our goal was to probe each of these configuration parameters to check its impact on model performance and efficiency. As a result, we reveal regions of model configuration space with an increased performance at a mild efficiency cost. We can roughly divide the hybrid model configuration space in the following 4 blocks:
- SSM specific parameters. Our SSM layer is based on mamba-2 architecture that organized into groups of heads, similar to attention in modern transformer models. We have found that deviation of the number of groups or heads from the values typically used in the literature doesn’t improve performance but could degrade efficiency. In contrast, using a larger memory size, an SSM-specific variable that does not have an attention analog, gives a boost in performance with only a mild efficiency cost.
- Attention specific parameters. We employ a standard full attention layer. However, we have found that using an extremely large-scale parameter in rotary positional embeddings (RoPE) significantly improves the model performance. Our hypothesis is that, compared to pure transformers, in hybrid models such large values become possible since some positional information is natively processed by the SSM part of the model.
- Combining mamba and attention. There are many ways to combine attention and SSM in one model, with a sequential or parallel approach being the main design choice. We have converged on the parallel approach demonstrated in the diagram above. The key feature of our parallel hybrid design is the possibility of adjusting the ratio of attention and SSM heads, where we have found that a relatively small fraction of attention is sufficient for good performance.
- General parameters. In our experiments we observed the increased model depth to have the largest impact on the performance, though at efficiency cost. This makes choosing the model’s depth a tough tradeoff that depends on specific use cases. Our Falcon-H1-1.5B-deep is motivated by this tradeoff and targets usage scenarios requiring maximal performance at a small parameter count.
Data strategy
Capabilities of language models are known to come mainly from the training data, and that stays true for Falcon-H1 series. Besides the raw data prepared for the model, it is crucial how and when this data is shown during training. One such data strategy is commonly called curriculum learning, where simpler data is shown at the beginning of the training while the samples requiring more advanced reasoning are left for the end. Surprisingly, a completely opposite strategy worked best for us. Giving even the most complicated data, an advanced math problem or a long context sample, from the beginning of the training seems to give the model more time to learn features essential for handling the respective complex tasks.
Another key aspect is the scarcity of high-quality data. A common concern when training large models is brute force memorization of the data as opposed to its real understanding. To minimize the risk of such memorization, a common practice is not reusing data samples during training, or doing it at most a few times for the highest quality samples. A by-product of this strategy is data mixture being dominated by web samples that have disproportionally large volume compared to high-quality sources. We have found that the memorization effect might be a bit overestimated, and carefully estimating model’s memorization window allows to reuse high-quality samples more often without any harm to model’s generalization ability.
Customized maximal update parametrization (μP)
Classical μP is a technique heavily rooted in theory of neural networks but with a clear practical application: if one finds optimal training hyperparameters at a single base model size, it can be effortlessly transferred to other, typically bigger, model sizes using Mup scaling rules. We employed Mup hyperparameter transfer for the whole Falcon-H1 series, greatly reducing experimentation time and making it possible to train 6 models in parallel.
On top of that, we made the next step into inner workings behind μP to further boost the model performance. In a nutshell, each component of the model “wants” to train at its own intensity, and that intensity depends on the size of the component. μP scaling rules take into account this dependence through so-called ``μP multipliers’’ to enable optimal hyperparameter transfer. However, classical μP uses trivial multipliers of 1 at the base model size, which corresponds to a nasusmption that intensity of all components are already optimal at the base size. We discard this assumption and tune the multipliers at the base model size. Specifically, we have divided model parameters into 35 fine-grained groups and performed a joint optimization of the respective 35 multipliers.
Training dynamics
One of our first steps in working on Falcon-H1 series was treating and removing spikes that are known to be a serious issue for SSM-based models. The solution that has worked the best for us is placing dampening μP multipliers at a certain location of the SSM block. In addition to the smooth final model training, the removal of spikes is essential to get clean signals in the subsequent experiments.
We have observed that many aspects of the training dynamics are linked together under a common theme of noise interpretation and control. This includes learning rate and batch size schedules, scaling of the learning rate with batch size, and the behavior of parameter norms. In particular, we have found the parameter norms to be mostly determined by the training hyperparameters rather than the model fitting the data. To take this into account, we have included weight decay, a hyperparameter that primarily controls parameter norms, into both the training schedule and μP multipliers.
Performance
Instruct Models
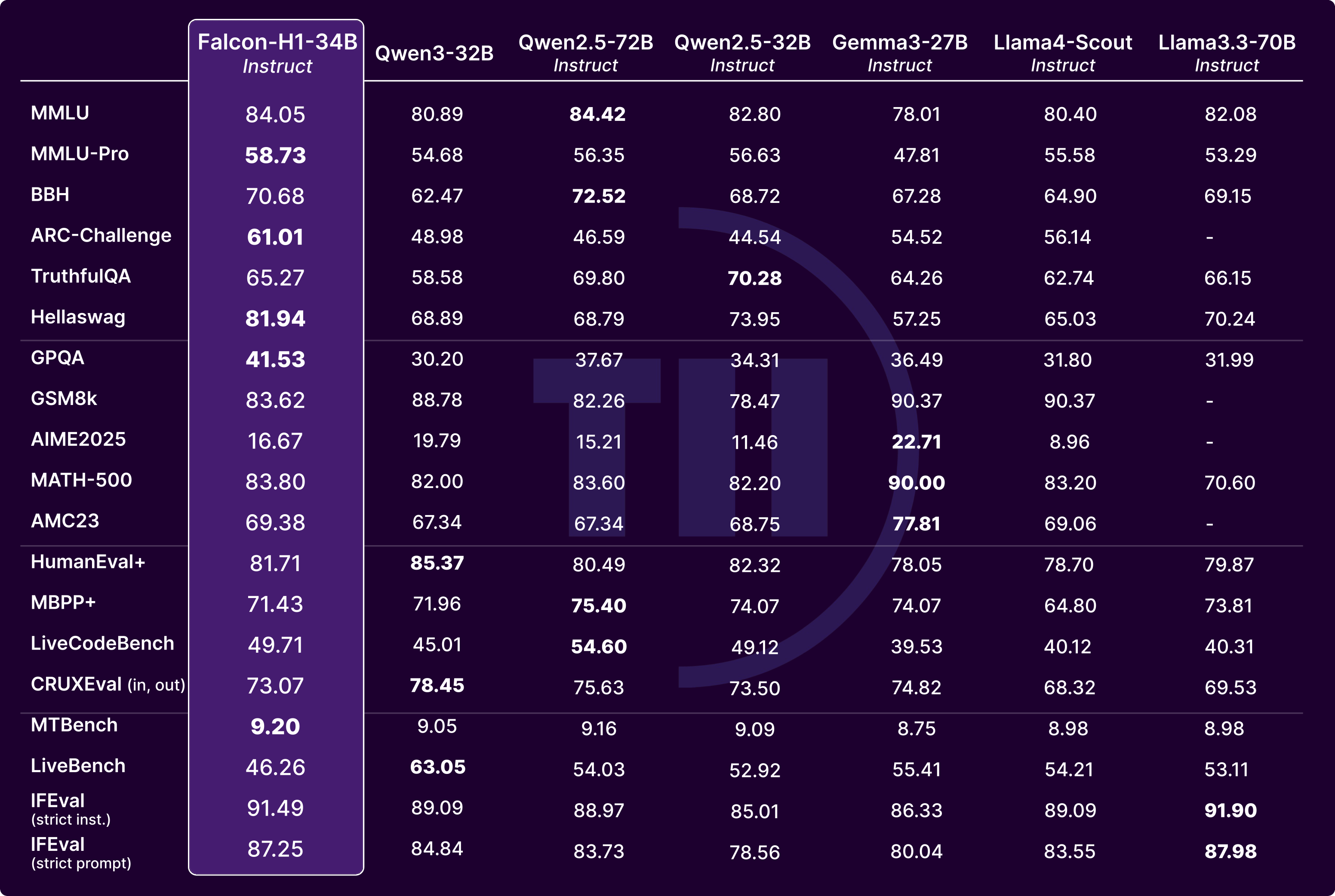
The current Falcon-H1 models were trained without reasoning-specific fine-tuning, yet they already demonstrate strong general instruction-following capabilities. To highlight their performance, we present a detailed comparison of Falcon-H1-34B-Instruct against other top-performing Transformer models of similar or larger scales, including: Qwen3-32B (non-thinking mode), Qwen2.5-72B, Qwen2.5-32B, Gemma3-27B, Llama-4-Scout-17B-16E (109B) and LLaMA3.3-70B. For full evaluation settings and methodology, please refer to the Falcon-H1 GitHub page.
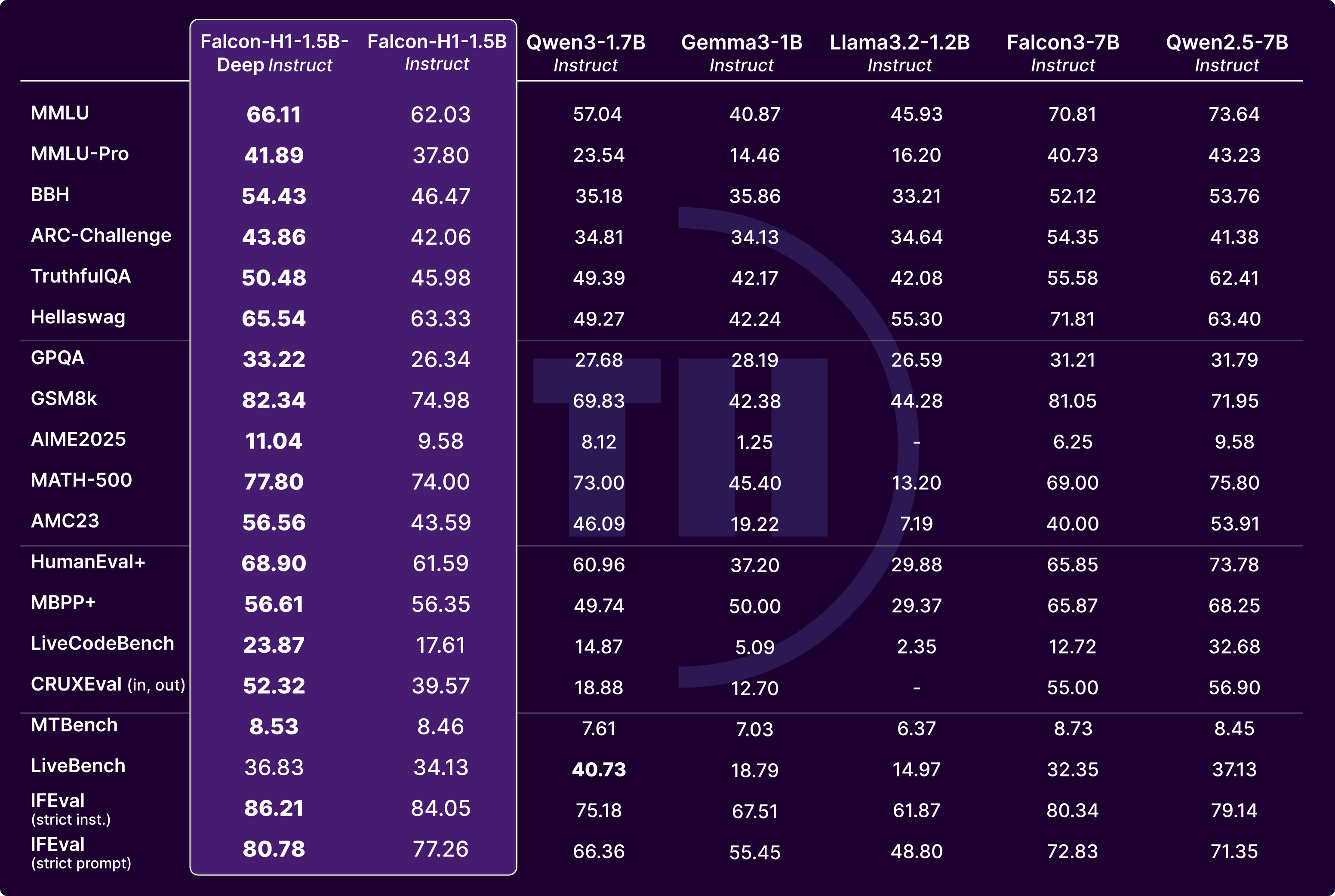
One of the standout features of the Falcon-H1 series is the strong performance of its compact models. Below, we compare 1.5B-scale instruct models. Falcon-H1-1.5B-Deep-Instruct clearly outperforms leading models in its class, such as Qwen3-1.7B-Instruct. Even more notably, it performs on par with—or better than many 7B models, including Falcon3-7B-Instruct and Qwen2.5-7B-Instruct.
🔎 Note: Falcon-H1-1.5B-Deep and Falcon-H1-1.5B were trained using identical settings; the only difference lies in their architectural depth and width.
Multilingual Benchmarks
To give a picture of Falcon-H1 performance across languages, we provide average between Hellaswag and MMLU scores for 30B scale models and for a set of selected languages, including Arabic, German, Spanish, French, Hindi, Italian, Dutch, Portuguese, Romanian, Russian, and Swedish. It also demonstrates on-par performance in the other supported languages.
Long Context Benchmarks
One of the standout features of Falcon-H1 is its ability to handle long-context inputs, an area where State Space Models (SSMs) offer significant advantages in terms of memory efficiency and computational cost.
To demonstrate these capabilities, we evaluate Falcon-H1-34B-Instruct against Qwen2.5-72B-Instruct across a set of long-context benchmarks. We focus on three core task categories drawn from the Helmet benchmark suite - Retrieval-Augmented Generation (RAG): Natural Questions, TriviaQA, PopQA, HotpotQA; Recall tasks: JSON KV, RULER MK Needle, RULER MK UUID, RULER MV; Long Document QA tasks: ∞BENCH QA, ∞BENCH MC. These evaluations highlight Falcon-H1’s strength in scaling to longer sequences while maintaining high performance and efficiency.
In addition, we conducted a comprehensive evaluation of the Falcon-H1 series alongside leading Transformer-based models across 23 benchmarks, covering multiple domains and model scales. You can explore the interactive results below—simply select the benchmarks most relevant to your use case to view the corresponding aggregated performance scores.
Base Models
We provide a detailed comparison of Falcon-H1-34B-Base with other leading base models at the same or larger scale, including Qwen2.5-72B, Qwen2.5-32B, Llama-4-Scout-17B-16E (109B) and Gemma3-27B.
🔎 Note: Qwen3-32B does not currently offer a base model checkpoint.
Below, we compare 1.5B-scale base models. Falcon-H1-1.5B-Deep-Base clearly outperforms leading models in its class, such as Qwen3-1.7B-Base. Notably, it performs on par with Falcon3-7B, and even exceeds it on math and reasoning tasks, making it an excellent foundation for building small-scale reasoning-focused models.
For the base models, we also provide an interactive plot showcasing their performance across 14 benchmarks, spanning multiple domains and various model scales.
Model Efficiency
We compare input (prefill) and output (generation) throughput between Falcon-H1 and Qwen2.5-32B in the plots below. While Transformers are slightly faster at shorter context lengths, our hybrid model becomes significantly more efficient as the context grows—achieving up to 4× speedup in input throughput and 8× in output throughput at longer sequence lengths. Benchmarks were run using our Falcon-H1 vLLM implementation and the official vLLM implementation of Qwen2.5-32B.
This performance gain highlights the scalability of the Falcon-H1 architecture. We attribute the throughput gap at small context lengths to the more mature optimizations of attention mechanisms, compared to current State Space Models (SSMs) implementations, in current inference pipelines.
⚙️ We invite the community to contribute to further optimizing SSM implementations — a promising direction for advancing the next generation of efficient LLMs.
Prompt Examples
Below are a few example outputs generated by Falcon-H1-34B-Instruct.
Open Source Commitment
In line with our mission to foster AI accessibility and collaboration, Falcon-H1 is released under the Falcon LLM license. We hope the AI community finds these models valuable for research, application development, and further experimentation. Falcon-H1 is a continuation of our efforts to create more capable and efficient foundation models. We welcome feedback and collaboration from the community as we continue to refine and advance the capabilities of these models.
Useful Links
- Access to our models (including GPTQ and GGUF) through the Falcon-H1 HuggingFace collection.
- Check out our Github page for the latest technical updates on Falcon-H1 models.
- Feel free to join our discord server if you have any questions or to interact with our researchers and developers.
- Check out the Falcon-LLM License link for more details about the license.
Citation
@article{falconh1,
title={Falcon-H1: A Family of Hybrid-Head Language Models Redefining Efficiency and Performance},
author={Jingwei Zuo and Maksim Velikanov and Ilyas Chahed and Younes Belkada and Dhia Eddine Rhayem and Guillaume Kunsch and Hakim Hacid and Hamza Yous and Brahim Farhat and Ibrahim Khadraoui and Mugariya Farooq and Giulia Campesan and Ruxandra Cojocaru and Yasser Djilali and Shi Hu and Iheb Chaabane and Puneesh Khanna and Mohamed El Amine Seddik and Ngoc Dung Huynh and Phuc Le Khac and Leen AlQadi and Billel Mokeddem and Mohamed Chami and Abdalgader Abubaker and Mikhail Lubinets and Kacper Piskorski and Slim Frikha},
journal = {arXiv preprint arXiv:2507.22448},
year={2025}
}
Core Contributors

Jingwei Zuo
Maksim Velikanov
Ilyas Chahed
Younes Belkada
Dhia Eddine Rhayem
Guillaume Kunsch
Additional Contributors
Falcon LLM team